关键词:人力资源;基于案例推理;推荐算法
1 背景
北京 AI 公司是一家是领先的中国全电信软件解决方案提供商.AI 公司自成立以来,始终站在世界技术的前沿,推动中国新一代电信的发展.AI 公司总部设在北京中关村,在全国各地乃至新加坡、印度均设有机构,员工人数将近 2 万多名,2001 年总收入达 18900 万美元.曾被世界经济论坛评为全球 500 家高速成长的企业之一.
近年来,随着社会的发展,企业与员工的关系,将不再是简单的劳资关系,而是通过若干维度的紧密连接,形成的一个全面的生存共同体,人类社会已经进入到了新经济时代.知识经济是以人力资本投入为主的经济,充分利用人才资本和知识是这个时代的强大精神体现.人力资源不仅是最积极、最活跃的生产要素,而且毫无疑问是最重要的第一生产要素.[1]
2 相关技术理论案例相似度算法:
案例的全局相似性算法采用加权局部相似度量如[3]
下Sim(X,Y)=ni=1ΣwjSim(Xi,Yi)其中,Sim(X,Y)表示目标案例 X 与源案例 Y 的相似度,wj表示特征 i 的权重,Sim(Xi,Yi)表示目标案例 X 与源案例 Y 在特征 i 上的相似度,相似度计算实质上就是对属性间距离进行度量,Sim(X,Y)应当满足以下的条件和性质[4][5]
①sim (X,Y)∈[0,1]
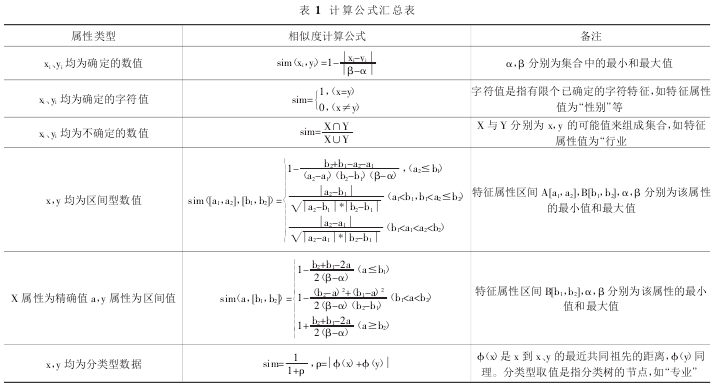
②当且仅当 X=Y,sim(X,Y)=1③sim (X,Y)=sim(Y,X)④sim (X,Y)≥sim(X,Z)+sim(Z,Y)-1本文中两种类型用户的属性之间的相似度计算公式如表 1 所示.
3 模型设计
3.1 用户类型的设计
用户在登录推荐系统前,可以根据自己的求职意向,在 AI 公司人才档案系统更新自己的求职意向.本文会以用户在人才档案系统存储的最新用户信息为基础,同时根据系统用户登录的行为将用户分为:首次登录系统用户和非首次登录系统用户.
对于在 AI 公司人才档案系统里面修改简历信息或者求职意向的用户,系统会根据用户修改后的用户信息,为用户进行职位推荐;对于首次登录系统对用户,系统会采用基于案例推理的算法为用户提供推荐服务,否则,系统会根据用户的行为数据,采用基于模型的协同过虑算法为用户提供推荐服务.
3.2 推荐模型的设计
经查阅相关文献可知,影响职位推荐列表等影响因素有很多,并且每一种影响因素对最终推荐列表的影响程度均是不同的.因此,本文采用层次分析法[6](The analytichierarchy process)简称 AHP,来确定不同属性信息权重.该方法的具体步骤如下:
3.2.1 建立层次结构模型
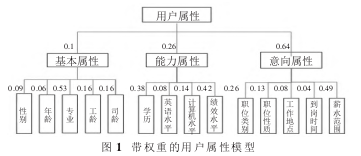
根据 AI 公司的业务需求,并结合相关文献知识,本文将影响最终职位推荐列表的属性信息分为用户属性及职位属性.用户属性包括用户基本属性、用户能力属性、用户意向属性.
3.2.2 成对比较矩阵
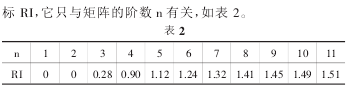
在确定权重时,Satty 等人提出一致矩阵法,成对比较矩阵中 aij 的取值,尽可能的降低因元素性质不同而难以比较的难度.比较矩阵的元素可参考 Satty 提议的标度表进行赋值.用成对法比较得到的成对比较矩阵 A 如下:1/1 1/3 1/53/1 1/1 1/35/1 3/1 1/≥1对应的特征向量为 Z=(0.1506,0.3715,0.9161)3.2.3 相似度一致性检测衡量矩阵 A 不一致程度的指标 CI 计算公式如下:CI=λmax(A)-nn-1(1)从有关资料可查出成对比较矩阵 A 的随机一致性指
由上式得CI=0.0195,其中 λmax=3.1085,n=3.
所以成对比较阵 A 的随机一致性比率 CR 可由公式(2)表示.CR=CIRI(2)
因此,CR=0.0332<0.1,对特征向量进行归一化得:U=(0.1047,0.2583,0.6370)因此该向量为计算的求职者属性的下三个属性的权向量.同理计算出其他属性的权向量.结果图 1 所示.
4 基于案例推理的推荐
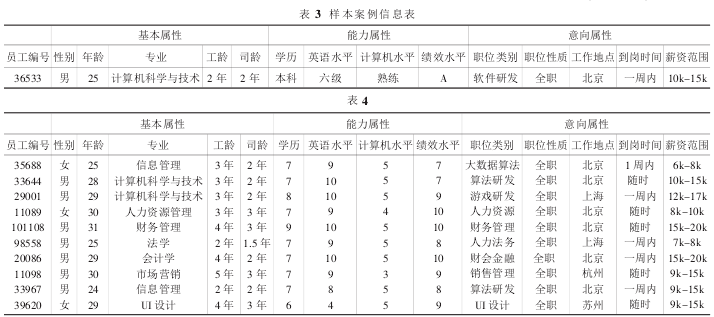
本文模拟一位有转岗需求且符合 AI 公司转岗要求的用户,在历史案例库里面随机抽取 10 个案例进行实验,该用户的详细信息如表 3.
从历史案例库中选取 10 个成功的求职案例,并进行纲量化,可得出表 4.
计算过程:①基本属性的相似度计算如下:sim(1,X)1=0.09*0+0.06*1+0.53*13+0.16*23+0.16*1=
0.503②能力属性相似度计算如下:
sim(1,X)2=0.38*1+0.08*56+0.14*1+0.42*13=0.727③意向属性相似度计算如下:
sim(1,X)3=0.26*13+0.13*1+0.08*1+0.04*1+0.49*2姨10=0.647因此,历史案例与目标案例的综合相似度为:
sim(1,X)=0.1*sim(1,X)1+0.26*sim(1,X)2+0.64*sim(1,X)3=0.653同理计算出其他属性综合相似度并由大到小排列为:
0.788>0.787>0.765>0.677>0.675>0.666>0.654>0.653>0.650>0.416因此我们将这些相似度排在前 5 名对应的员工的职位推荐给目标用户.
参考文献:
[1]赵柳.人力资源权益模式研究[D].成都:西南财经大学,2011:1-2.
[2]梁艳.基于基于案例推理的职位推荐[D].河北师范大学,2012.
[3]任凯,浦金云.基于案例属性特征区间相似度的改进算法研究[J].控制与决策,2010,25(1):308-310.
[4]黄正.协同过滤推荐算法综述[J].价值工程,2012,21(1),226-228.
[5]杜淼.两类层次分析法的转换及在应用中的比较[J].计算机工程与应用,2012,48(9):114-119.